Analyser des PDF facilement grâce à l'API Mistral AI
Publié le
Automatise l'analyse de documents PDF grâce à l'IA générative en intégrant l'API Mistral AI dans tes applications Symfony pour extraire des infos clés facilement !
Aujourd’hui, je t’invite à découvrir un cas d'usage très intéressant de l’IA générative : la création d’un système d’analyse et d’extraction des informations essentielles depuis des documents PDF, en s’appuyant sur l’API Mistral AI : que tu aies besoin de synthétiser des rapports techniques complexes, d’identifier des informations spécifiques dans des contrats, de structurer des données issues de documents administratifs, tu trouveras ici des réponses adaptées à tes besoins. Dans la deuxième partie, nous verrons comment intégrer cette fonctionnalité dans un prototype développé avec Symfony.
Mistral AI : La solution française pour explorer l'IA générative
Si tu n’as pas passé les trois dernières années dans une grotte, tu as forcément entendu parler du bouleversement provoqué par l’IA générative. Mais si tu as besoin d’un petit rattrapage, je te recommande de jeter un œil à cet article pour tout comprendre et te mettre à jour.
Mistral AI est une entreprise française spécialisée dans les solutions d’intelligence artificielle générative. Elle propose notamment un chatbot, sobrement nommé Le Chat, ainsi qu’une API permettant de faciliter l’intégration de processus d’IA générative dans des applications. Mistral AI met à disposition plusieurs modèles, avec de nombreuses variantes, incluant des versions multimodales et des versions open source.
Pourquoi j'ai choisi d'utiliser Mistral pour ce cas pratique ?
Premièrement, Mistral AI est une entreprise française. Au-delà de l’aspect patriotique (cocorico !), je pense qu’il sera plus facile de se conformer au RGPD en utilisant des solutions où les données sont traitées en Europe.
Ensuite, Mistral propose une offre "Expérimentation" qui permet d’utiliser son API gratuitement. Toutefois, sois prudent avec cette offre : Mistral se réserve le droit d’utiliser tes requêtes, et donc tes données, pour améliorer ses services. Si tu envisages de les utiliser en production, je te recommande de t’orienter vers l’offre payante. Ici, dans le cadre d’un prototype, l’offre expérimentale sera tout à fait adaptée (j’éviterais simplement de lui faire analyser mon relevé d’impôt ou mon casier judiciaire 😱).
Pour finir, l’API de Mistral est facile et rapide à mettre en œuvre, surtout si tu as déjà interagi avec d’autres API. De plus, il y a quelque temps, en explorant leur service, j’ai découvert une fonctionnalité non documentée (à l’heure où j’écris ces lignes) qui va drastiquement nous simplifier la vie dans le cas d’usage présent.
Petit bonus : si tu as déjà utilisé l’API de ChatGPT, celle de Mistral est très similaire (c’est même troublant 🤔).
Comment analyser des PDF avec l'API Mistral ?
Une capacité non documentée mais fort pratique
Lors de mes premières réflexions sur l’analyse de documents, je pensais extraire le contenu du PDF moi-même à l’aide d’une solution tierce, puis transmettre ce contenu au format Markdown à l’API. Cependant, une question restait en suspens : quid des illustrations, des photos ou des tableaux complexes ?
En parcourant la documentation, j’ai découvert qu’il était possible de transmettre à l’API un texte ou l’URL d’une image. À ce moment-là, une idée m’est venue : plutôt que d’extraire manuellement le contenu du document, je pourrais le convertir en image et la transmettre pour analyse.
Avant même de me plonger dans la conversion du PDF en image, j’ai réalisé quelques tests. En commettant une erreur d’implémentation, je suis tombé sur ce message d’erreur :
Input tag 'image_file' found using 'type' does not match any of the expected tags: <ChunkTypes.text: 'text'>, <ChunkTypes.image_url: 'image_url'>, <ChunkTypes.document_url: 'document_url'>, <ChunkTypes.reference: 'reference'>, <ChunkTypes.bbox: 'bbox'>, <ChunkTypes.file_url: 'file_url'>
Je m’étais trompé dans la valeur du type, mais ce message m’a intrigué : il mentionnait une valeur document_url que je n’avais jamais vue dans la documentation. Me sentant en veine, j’ai tenté le coup en transmettant l’URL d’un PDF avec le type document_url. Et là, surprise : ça a parfaitement fonctionné 🎉.
Je n’avais donc même pas besoin de convertir le document en image : il suffisait simplement que mon PDF soit accessible via une URL publique, simple et efficace !
Récupération d'une clé d'API
Il est temps de réaliser nos premiers appels API pour expérimenter tout ça. Mais avant toute chose, nous allons avoir besoin d’une clé d’API pour nous authentifier auprès du service.
La procédure est assez simple. Le seul bémol : la nécessité de confirmer un numéro de téléphone (mais pas besoin de carte bancaire, heureusement). Voici les étapes à suivre :
- Se rendre sur la console Mistral.
- Créer un compte.
- Choisir le plan tarifaire (dans notre cas, le plan "Expérimentation").
- Se rendre sur la page des clés d’API.
- Cliquer sur le bouton "Créer une nouvelle clé d’API".
Et voilà ! Notre clé d’API apparaît comme par magie sous nos yeux ébahis.
Premier essai, premier succès
Il est temps de parcourir la documentation pour construire notre premier appel API. Le point de terminaison qui nous intéresse est /v1/chat/completions.
Intéressons-nous maintenant à la charge utile de la requête, qui devra être au format JSON. Dans notre cas, nous aurons besoin de trois clés principales :
model: Ce paramètre définit le modèle utilisé. Mistral propose plusieurs modèles, dont deux ont retenu mon attention :mistral-large-latest, le modèle phare de l’entreprise, etpixtral-large-latest, une version multimodale permettant notamment l’analyse d’images. J’ai choisi ce dernier pour sa polyvalence, mais n’hésite pas à tester d’autres modèles pour trouver celui qui correspond à ta situation.response_format: Ce paramètre détermine le format de la réponse. Nous opterons pour du JSON, plus simple à exploiter que du texte brut.messages: Cette clé permet de transmettre les prompts. Nous utiliserons trois prompts : un prompt système pour décrire notre besoin général d’analyse documentaire, un premier prompt utilisateur pour transmettre le lien du document, et un second prompt utilisateur pour permettre à l’utilisateur de préciser sa demande sur le document.
Il nous faut donc réfléchir quelques minutes pour rédiger ce fameux prompt système. Enfin, quand je dis réfléchir, on va plutôt demander à ChatGPT (oui, j’ai vraiment demandé à ChatGPT de rédiger un prompt pour Mistral, je suis taquin, mais surtout, j’ai déjà obtenu des résultats intéressants avec cette méthode).
Le prompt aura pour objectif de :
- Poser le contexte : Expliquer à Mistral que nous souhaitons qu’il analyse notre document.
- Préciser le format de retour : Indiquer que la réponse doit être au format JSON (il est parfois utile de le rappeler, même si le paramètre
response_formatest déjà défini) et que les contenus doivent être rédigés en français. - Décrire la structure du JSON : Fournir une description assez précise de la structure attendue pour le JSON.
Après quelques allers-retours avec ChatGPT et plusieurs ajustements, voici le résultat :
Tu es une IA spécialisée dans l'analyse de documents.
Ta tâche est d’analyser le PDF fourni et de retourner une réponse strictement au format JSON.
Le JSON doit respecter cette structure :
{
"document_type": "string",
"language": "string",
"page_count": "integer",
"document_date": "string",
"user_response": "string"
}
document_type : Catégorie du document (ex. : "facture", "contrat", "rapport").
language : Langue principale du document (code ISO 639-1, ex. : "fr", "en").
page_count : Nombre total de pages du document.
document_date : Date de création ou de mise à jour du document, uniquement si elle est disponible dans le document (format ISO 8601, ex. : "2024-01-29").
user_response : Réponse au prompt utilisateur en fonction du contenu du document, uniquement sous forme de texte.
C’est assez rudimentaire, mais cela reste suffisant pour avancer.
Il ne reste plus qu’à rassembler toutes les pièces du puzzle pour construire le payload de notre première requête :
{
"model": "pixtral-large-latest",
"response_format": {
"type": "json_object"
},
"messages": [
{
"content": "[Notre prompt système]",
"role": "system"
},
{
"content": [
{
"type": "document_url",
"document_url": "https://rdelbaere.fr/cv"
}
],
"role": "user"
},
{
"content": "Donne-moi une liste des technologies pratiquées par le candidat",
"role": "user"
}
]
}
Il n’y a plus qu’à envoyer notre requête en POST à l’URL https://api.mistral.ai/v1/chat/completions, avec une en-tête Authorization au format Bearer [API_KEY]. Et voici la réponse obtenue :
"content": {
"document_type": "CV",
"language": "fr",
"page_count": 1,
"document_date": "2024-01-29",
"user_response": "Symfony, Angular, NodeJS, Cordova, Wordpress, PHP, Drupal, C++, OpenSceneGraph, Qt, HTML, CSS, JavaScript"
}
Mise en place d'un prototype avec Symfony
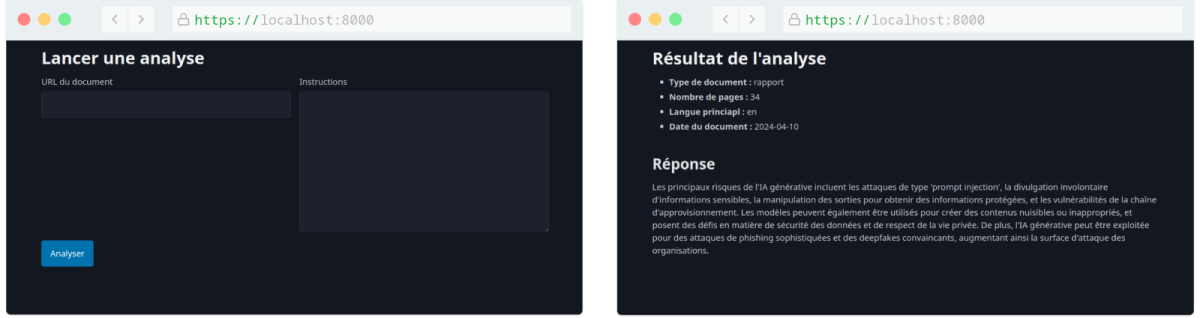
Il est temps d’implémenter notre prototype pour faciliter l’envoi des requêtes d'analyse. Celui-ci sera très simple : un formulaire avec deux champs (un pour l’URL et un pour les instructions utilisateur), ainsi qu’une vue pour afficher la réponse.
Je t’épargne la sempiternelle partie de l’article sur l’initialisation d’un projet Symfony. Si tu as besoin d’informations à ce sujet, je te redirige vers la documentation officielle.
Création du formulaire de demande d'analyse
Commençons par créer un modèle pour structurer les données de notre formulaire. Celui-ci comprendra :
- Deux propriétés : une pour l’URL du document et une pour les instructions utilisateur.
- Les getters et setters correspondants.
- Quelques contraintes de validation pour garantir l’intégrité des données.
<?php
namespace App\Model;
use Symfony\Component\Validator\Constraints as Assert;
class DocumentAnalysisRequest
{
#[Assert\NotBlank]
#[Assert\Url(requireTld: true)]
private ?string $documentUrl;
#[Assert\NotBlank]
private ?string $prompt;
public function getDocumentUrl(): ?string
{
return $this->documentUrl;
}
public function setDocumentUrl(string $documentUrl): static
{
$this->documentUrl = $documentUrl;
return $this;
}
public function getPrompt(): string
{
return $this->prompt;
}
public function setPrompt(?string $prompt): static
{
$this->prompt = $prompt;
return $this;
}
}
Ensuite, créons notre FormType basé sur notre modèle :
<?php
namespace App\Form;
use App\Model\DocumentAnalysisRequest;
use Symfony\Component\Form\AbstractType;
use Symfony\Component\Form\Extension\Core\Type\TextareaType;
use Symfony\Component\Form\Extension\Core\Type\UrlType;
use Symfony\Component\Form\FormBuilderInterface;
use Symfony\Component\OptionsResolver\OptionsResolver;
final class DocumentAnalysisType extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options): void
{
$builder
->add('documentUrl', UrlType::class, [
'label' => 'URL du document',
])
->add('prompt', TextareaType::class, [
'label' => 'Instructions',
])
;
}
public function configureOptions(OptionsResolver $resolver): void
{
$resolver->setDefaults([
'data_class' => DocumentAnalysisRequest::class,
]);
}
}
Création du service d'analyse pour communiquer avec l'API Mistral AI
Attaquons le plat de résistance : le service qui se chargera de préparer notre requête, d’interagir avec l’API et de désérialiser le résultat.
En parlant de désérialisation, nous allons également avoir besoin d’un autre modèle, basé sur la structure JSON décrite dans notre prompt système, pour contenir les informations renvoyées par le Chat.
<?php
namespace App\Model;
class DocumentAnalysisResponse
{
private string $documentType;
private string $language;
private int $pageCount;
public ?string $documentDate;
private string $userResponse;
public function getDocumentType(): string
{
return $this->documentType;
}
public function setDocumentType(string $documentType): static
{
$this->documentType = $documentType;
return $this;
}
public function getLanguage(): string
{
return $this->language;
}
public function setLanguage(string $language): static
{
$this->language = $language;
return $this;
}
public function getPageCount(): int
{
return $this->pageCount;
}
public function setPageCount(int $pageCount): static
{
$this->pageCount = $pageCount;
return $this;
}
public function getDocumentDate(): ?string
{
return $this->documentDate;
}
public function setDocumentDate(?string $documentDate): static
{
$this->documentDate = $documentDate;
return $this;
}
public function getUserResponse(): string
{
return $this->userResponse;
}
public function setUserResponse(string $userResponse): static
{
$this->userResponse = $userResponse;
return $this;
}
}
Notre service va nécessiter un peu de configuration. Commençons par ajouter un paramètre pour renseigner la clé d'API dans nos fichiers d’environnements :
MISTRAL_API_KEY=replace_me
Puis, rapatrions cette clé d’API et ajoutons quelques informations supplémentaires dans le fichier config/services.yaml :
parameters:
document_analyzer:
base_url: https://api.mistral.ai/v1
endpoint: /chat/completions
model: pixtral-large-latest
api_key: '%env(MISTRAL_API_KEY)%'
Et pour finir notre service :
<?php
namespace App\Service;
use App\Model\DocumentAnalysisRequest;
use App\Model\DocumentAnalysisResponse;
use Symfony\Component\DependencyInjection\Attribute\Autowire;
use Symfony\Component\Serializer\SerializerInterface;
use Symfony\Contracts\HttpClient\HttpClientInterface;
final readonly class DocumentAnalyzer
{
private const DEFAULT_PROMPT = '[Prompt système à retrouver ci-dessus]';
public function __construct(
private HttpClientInterface $http,
private SerializerInterface $serializer,
#[Autowire('%document_analyzer%')] private array $config,
) {}
public function analyze(DocumentAnalysisRequest $analysisRequest): DocumentAnalysisResponse
{
$payload = [
'model' => $this->config['model'],
'response_format' => [
'type' => 'json_object',
],
'messages' => [
[
'content' => self::DEFAULT_PROMPT,
'role' => 'system',
],
[
'content' => [
[
'type' => 'document_url',
'document_url' => $analysisRequest->getDocumentUrl(),
],
],
'role' => 'user',
],
[
'content' => $analysisRequest->getPrompt(),
'role' => 'user',
],
],
];
$url = sprintf('%s%s', $this->config['base_url'], $this->config['endpoint']);
$response = $this->http->request('POST', $url, [
'headers' => [
'Content-Type' => 'application/json',
'Authorization' => sprintf('Bearer %s', $this->config['api_key']),
],
'json' => $payload,
]);
$responseData = $response->toArray();
$chatData = $responseData['choices'][0]['message']['content'];
return $this->serializer->deserialize($chatData, DocumentAnalysisResponse::class, 'json');
}
}
- On commence par injecter le
HTTPClientpour effectuer la requête, leSerializerpour désérialiser la réponse et la configuration que nous avons définie dans le fichierconfig/services.yamlgrâce à l’attribut#[Autowire]. - On définit la méthode
analyse, qui prend en entrée notre modèle de requête utilisateur et retourne notre modèle de réponse. - On continue avec la construction du payload de notre requête, en reprenant les éléments utilisés lors de notre premier test.
- On envoie la requête en
POSTavec leHTTPClient, en veillant à ajouter l’en-têteAuthorizationcontenant la clé d'API. - Pour terminer, on retourne la réponse du chatbot, désérialisée en un objet de type
DocumentAnalysisResponse.
Mise en place du contrôleur pour lancer une analyse
Mettons en œuvre tout ce beau monde avec un contrôleur :
<?php
namespace App\Controller;
use App\Form\DocumentAnalysisType;
use App\Model\DocumentAnalysisRequest;
use App\Service\DocumentAnalyzer;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\HttpFoundation\Response;
use Symfony\Component\Routing\Attribute\Route;
#[Route(name: 'app_document_analysis_')]
final class DocumentAnalysisController extends AbstractController
{
public function __construct(private DocumentAnalyzer $documentAnalyzer)
{
}
#[Route(path: '/', name: 'analyze')]
public function analyze(Request $request): Response
{
$analysisRequest = new DocumentAnalysisRequest();
$form = $this->createForm(DocumentAnalysisType::class, $analysisRequest);
$form->handleRequest($request);
if ($form->isSubmitted() && $form->isValid()) {
$analysisResponse = $this->documentAnalyzer->analyze($analysisRequest);
return $this->render('document_analysis/result.html.twig', [
'response' => $analysisResponse,
]);
}
return $this->render('document_analysis/analyze.html.twig', [
'form' => $form->createView(),
]);
}
}
On crée un template très simple pour notre formulaire, j'ai quand même ajouté Pico CSS pour la forme :
{% extends 'base.html.twig' %}
{% block title %}Lancer une analyse - {{ parent() }}{% endblock %}
{% block body %}
<h1>Lancer une analyse</h1>
{{ form_start(form) }}
<div class="grid">
{{ form_row(form.documentUrl) }}
{{ form_row(form.prompt) }}
</div>
<button>Analyser</button>
{{ form_end(form) }}
{% endblock %}
Et un autre tout aussi simple pour l'affichage de la réponse :
{% extends 'base.html.twig' %}
{% block title %}Résultat de l'analyse - {{ parent() }}{% endblock %}
{% block body %}
<h1>Résultat de l'analyse</h1>
<ul>
<li>
<strong>Type de document :</strong> {{ response.documentType }}
</li>
<li>
<strong>Nombre de pages :</strong> {{ response.pageCount }}
</li>
<li>
<strong>Langue princiapl :</strong> {{ response.language }}
</li>
<li>
<strong>Date du document :</strong> {{ response.documentDate ?? 'Aucune date' }}
</li>
</ul>
<h2>Réponse</h2>
<p>
{{ response.userResponse }}
</p>
{% endblock %}
Et voilà !
Tu peux retrouver l'ensemble du code du prototype sur notre Github.
Améliorations et limitations
Ce prototype porte bien son nom : il s’agit d’une version simple et naïve de notre cas d’usage. Je te suggère quelques améliorations si tu souhaites industrialiser cette méthode ou simplement approfondir le sujet.
Dans un premier temps, le code est largement perfectible. Notre service unique enfreint plusieurs principes SOLID. Il pourrait être intéressant d’améliorer l’architecture du prototype. La gestion de notre clé d’API à travers les fichiers d’environnement, bien que très répandue, n’est pas la méthode la plus sécurisée. J’ai fait le minimum syndical en termes de validation des données du formulaire et de gestion des erreurs de l'API.
En bonus, il est possible d’obtenir un retour textuel formaté en Markdown sur simple demande dans le prompt système : en passant ce contenu dans le filtre Twig markdown_to_html, tu obtiendras une mise en forme rapide et efficace de la réponse. Le contenu sera bien plus lisible, surtout pour les retours longs et détaillés.
Ensuite, un usage efficace de l’IA générative nécessite une longue phase de tests et d’ajustements propre à chaque besoin métier. Le prompt système est rudimentaire : ses instructions sont simples et peu détaillées, ce qui laisse de la place à l’interprétation. Cela n’est pas toujours souhaitable avec l’IA générative. L’API possède plusieurs paramètres pour affiner le comportement du chatbot. Tu peux retrouver l’ensemble de ces paramètres dans la documentation de Mistral AI.
Il est l’heure de parler de sécurité. L’IA générative présente des risques qui peuvent impacter ton application de bien des manières : de l’injection de prompt à la fuite de données, en passant par les erreurs et hallucinations. Si tu veux en apprendre plus, je te recommande de commencer par cet article sur les vulnérabilités critiques des LLM.
Je te recommande de bien prendre en compte ces aspects avant d’envisager l’usage d’une telle fonctionnalité en production.
Conclusion
L’IA générative offre de nombreuses opportunités pour enrichir nos applications. À mon humble avis, elle n’est pas toujours aussi efficace et polyvalente qu’on veut bien nous le faire croire, mais elle se montre pourtant diablement utile dans bien des situations. C'est notamment le cas pour l’analyse de documents.
L’intégration d’IA au travers d’une plateforme SaaS comme ChatGPT ou Mistral n’est pas forcément la plus économique ni la plus fiable en termes de confidentialité des données. Néanmoins, ces plateformes offrent une rapidité et une simplicité de mise en œuvre non négligeables.
Pour finir, Mistral est une alternative crédible face à Claude ou ChatGPT. Bien qu’un brin en retard sur ce dernier, cette plateforme française présente des avantages à ne pas négliger.
J’espère que cet article vous a plu et je vous dis à bientôt pour d’autres pérégrinations techniques sur ce blog ou sur Twitch 👋